
用有言,
创作你的3D数字人AI视频
一、拍摄现场的"档期黑洞":为什么真人出镜难以规模化?
在传统的视频内容产出模式中,人才是最大的变量。企业在打造品牌IP或录制内部课程时,往往面临以下真实困境:
- 成本与档期冲突: 邀请企业高管或外部专家录制视频,协调档期往往长达数周。光是租赁演播室、组织摄制组入场,单次成本就可能在数千至数万元之间。
- 容错率极低: 拍摄过程中一旦出现口误或后期内容更新,往往需要推倒重排,导致制作周期陷入"3-5天"的死循环。
- 产能瓶颈: 真人精力和体能有限,无法在短时间内产出适配不同地域、不同方言的海量视频内容。
人物克隆功能的出现,将"视频生产"从依赖个体劳动力转向依赖数字生产力,让企业能够沉淀核心人物资产,实现内容生产的"无限扩容"。
二、有言核心能力一:人物形象克隆机制
图生人脸与3D高精度建模
- 技术原理:基于少量平面的2D照片,算法自动推算人脸的三维骨骼与面部拓扑结构。
- 感知效果:生成的不是只有嘴巴会动的纸片人,而是拥有细腻皮肤纹理、毛发细节及立体五官的超写实3D虚拟人,支持多角度观看与运镜切换。
面部控制点与语义动作映射
- 技术原理:打通面部300+控制点与文本语义情感分析引擎,根据文案自动演算肢体表达。
- 感知效果:克隆出的数字人在播报时,微表情(如挑眉、眨眼)与肢体动作会紧随文案的情绪自然起伏,彻底告别“干瞪眼”的假人感。
三、有言核心能力二:专属音色克隆机制
少样本高精度声纹复刻
- 技术原理:利用先进的声纹识别神经网络,精准提取极短音频中的发音与共鸣特征。
- 感知效果:无需在录音棚连续朗读数小时,只需提供10秒发音清晰的音频,即可生成与真人音色、语气高度一致的专属AI声音,具有极高的个人辨识度。
跨语言高动态情感同步
- 技术原理:底层大模型打通了跨语种的发音逻辑映射,并与3D数字人的口型动作高精度关联。
- 感知效果:即便只录制了一段中文音频,专属声音也能自然流畅地讲出百余种外语;且带有呼吸感的声音能与数字人的口型实现98%以上的精准同步。
四、场景验证:形象与音色克隆如何赋能企业核心业务?
品牌代言数字化:视觉与声音,缺一不可
品牌方常面临代言人合约到期或形象受损的风险。通过 3D数字人资产与形象定制,企业可以打造永久属于自己的虚拟代言人 IP;与此同时,音色克隆让品牌声音同样成为可沉淀的资产——同一个声音可以在不同产品线、不同语言市场的视频中持续输出,无需反复邀请配音演员,确保品牌声音在全渠道的绝对统一。
光大证券面对传统拍摄周期长(3-5天)的痛点,借助人物与音色克隆定制数字分身,将制作周期压缩至几分钟,实现了"首席之声"视频号的稳定日更,制作成本从数万元降至几十元。
培训讲师资产化:声音比形象更难被复制,但现在可以了
企业大规模扩充或产品快速迭代时,讲师无法亲临每个门店进行 SOP 培训。不仅如此,资深讲师退休或离职后,其授课风格与语音特征往往随之流失。
音色克隆能够将讲师的声音特征永久保留为企业资产——即便讲师本人不在,PPT转数字人视频 依然可以用他的声音讲解最新课件。形象克隆则进一步将讲师的面部特征数字化,实现知识的无损传承。
伊利集团全球人才发展中心面对老员工经验难传承、全球化制作耗时耗力的挑战,借助批量课程生成与 3D 数字人克隆,合作不足一年已产出 2000+ 条培训课程,总播放时长突破 2 万分钟。
专家内容破圈:音色克隆独立使用,比出镜门槛更低
法律、医疗、金融等专业领域的内容创作者,往往面临"专家不愿出镜"与"内容必须有专家背书"之间的矛盾。
音色克隆提供了一条阻力最小的路径:专家只需录制 10 秒音频授权声纹采集,后续所有科普视频均可由数字人用其声音讲解,专家不需要对着镜头,也不需要一遍遍重录。若专家同时完成照片采集,形象克隆可进一步还原其真实面貌;若专家不希望露脸,则可仅使用音色克隆,为平台内其他数字人角色配上专属声音。
中伦律所旨在通过数字化革新彰显前瞻性,面对复杂法律内容难通俗化传播的挑战,借助定制的法律数智官"爱伦ALLEN"(数字分身),以生动方式讲解复杂法律问题,助力律师平均年创收提升49%,成为业内标杆。
跨境传播:用同一个声音说全球语言
对于跨境营销团队而言,音色克隆是多语种内容生产效率的核心杠杆。品牌代言人或专属配音演员完成一次音色克隆后,其声音可通过 多语种TTS语音合成 以英语、日语、西班牙语、阿拉伯语等 100+ 种语言输出,且始终保持一致的音色质感与呼吸感——无需为每种语言单独寻找配音演员,彻底解决"出海内容配音不统一"的问题。
五、极简操作:如何快速召唤您的专属3D虚拟分身?
魔珐有言将复杂的AI训练过程封装为极简的交互界面,您可以分别完成形象与声音的克隆,再将它们合二为一。
人物形象克隆的3个步骤
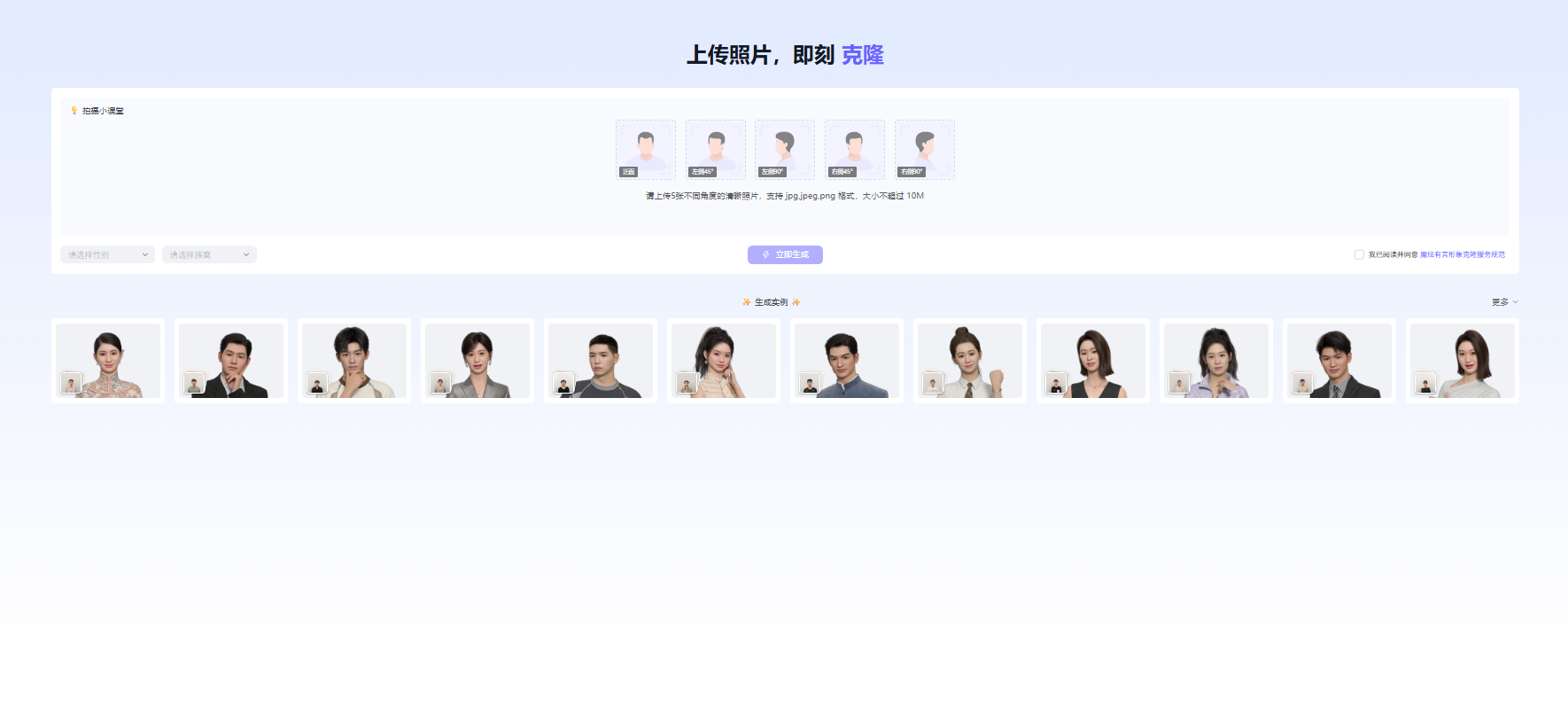
第1步:准备与上传合规照片素材
根据系统指南,拍摄或挑选5张光线均匀、面部无遮挡的不同角度真人半身照(如正脸、侧脸等)。登录工作台,进入“形象定制”模块打包上传。
第2步:极速建模与资产交付
系统利用强大的云端算力进行三维拓扑重建,您专属的高精度3D商用数字人模型可在资产库中激活。
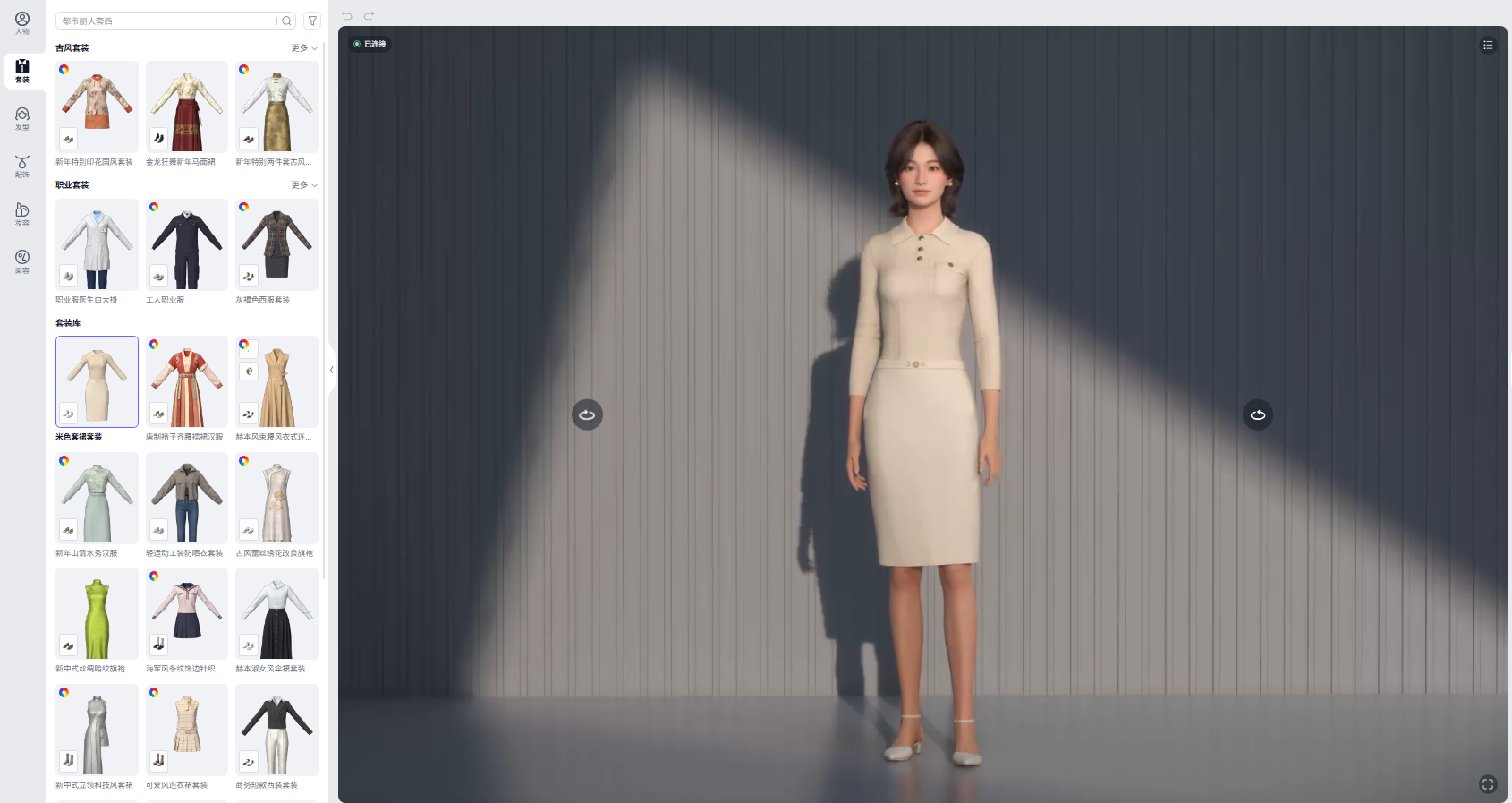
第3步:自由捏脸与换装搭配
交付后,您可以进入形象编辑器,为您的分身自由更换内置的各行业职业装、休闲服饰,甚至微调妆容与发型,适配不同的视频场景。
专属音色克隆的3个步骤
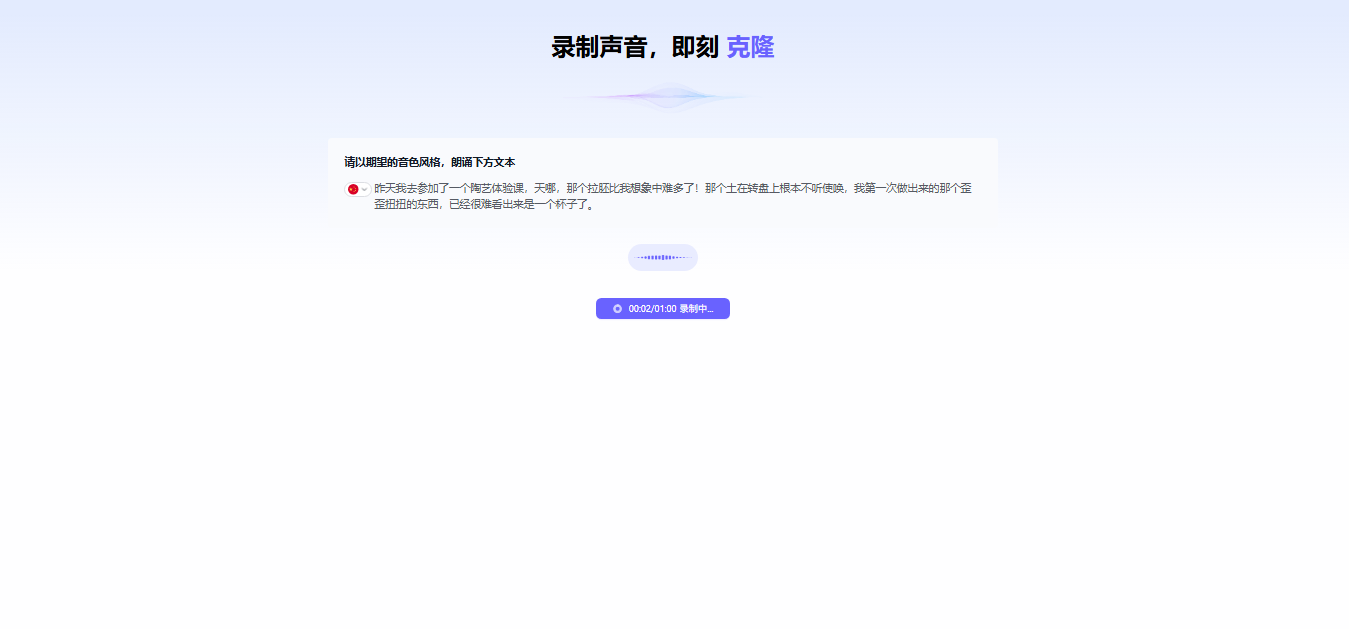
第1步:录制与上传短干声素材
在安静无回音的环境下,使用手机或录音设备录制一段左右、吐字清晰的语音(确保无背景音乐或底噪),进入“声音克隆”模块提交训练。
第2步:声纹极速建模与激活
系统将在云端极速完成声纹特征的提取与建模。专属声音激活后,它将永久保存在您的个人声音资产库中。
第3步:形神合体与一键成片
在视频创作工作流中,同时选中您的专属数字人模型与专属声音,在文本框中输入文案(支持一键翻译为外语)。点击渲染,系统即可自动计算口型与表情同步,产出形神兼备的原声原貌大片。
六、从“分身乏术”到“全天候IP输出”,您只差一次深度克隆
不要再让昂贵的摄制组和高管紧缺的时间限制您的品牌表达。利用魔珐有言的人物与音色双重克隆技术,将物理世界的专业智慧转化为永不枯竭的数字生产力,重塑企业的全渠道内容传播矩阵。
- 立即上传照片与录音,极速打造您的专属3D数字分身
[前往注册试用魔珐有言] - 查看名师、高管与虚拟代言人的专属数字分身应用案例
[探索更多行业IP打造成功实践] - 咨询企业级专属数字人IP及声音深度的闭环定制方案
[联系企业顾问获取高级定制报价] - 查看照片克隆与声音复刻完整操作与打光拍摄教程
[访问帮助中心学习素材准备规范]
七、关于AI人物与音色克隆的常见疑问
Q:克隆我的声音需要准备多久的音频素材?
A:我们的少样本声纹复刻技术非常高效。您通常只需准备10秒左右发音清晰、无明显背景噪音的短音频片段,系统就能在极短时间内精准复刻您的核心音色、语气和说话习惯。
Q:我录制了中文音频,我的克隆人能用原声讲英语吗?
A:完全可以。无论是声音还是形象模型,都具备强大的跨语种泛化能力。只需提取您的中文本色声纹,结合平台的TTS技术,您的数字分身就能无缝使用原声流利朗读英语、日语等百余种语言,轻松实现IP出海。
Q:为什么有的工具只需要一张照片几秒钟就能生成,你们要72小时?
A:只需几秒的工具本质上是“2D图像局部拉伸”,只能让嘴巴动,身体僵硬且效果极不自然。魔珐有言的72小时包含了高精度的三维骨骼拓扑重建、皮肤材质深度渲染与声纹多语种泛化训练,交付的是具备立体深度的真正3D数字资产。
Q:照片和声音克隆出来的数字人有知识产权纠纷吗?别人能随便用吗?
A:魔珐有言严格遵守数据安全及商用授权规范。企业级用户享有严格权限控制,您生成的专属数字人与声音模型仅限您的授权账号使用,从机制上杜绝了被盗用的风险。生成的视频内容商用版权均归您所有,完全支持全网商业变现。
Q:如果我不想用自己的脸和声音,可以直接捏一个全新的虚拟形象吗?
A:没问题。除了基于照片和录音的1:1真人克隆,系统还内置了3000+超写实模型与400+专业AI音色。您可以通过零门槛DIY功能自行组合五官、身形与声音,打造一个完全原创且零违约风险的虚拟代言人。


