
用有言,
创作你的3D数字人AI视频
一、为什么你的数字人看起来像"毫无温感的'复读机器'"?
在数字人视频普及的今天,许多企业发现制作出的视频虽有形象,却缺乏说服力。行业痛点主要集中在:音画脱节、表情僵死、语调平淡。用户在观看时会产生明显的"恐怖谷效应",这种僵硬感会直接稀释内容的专业度,导致完播率低、转化效果差。
究其原因,传统工具大多基于简单的唇形对位,无法理解文字背后的"重音、停顿与情感"。要让数字人真正从"能动"进化到"有神",必须依靠深层的语义理解与情感还原技术,这正是内容建立信任感的关键。
二、拆解魔珐有言:从算法逻辑到微表情重塑
魔珐有言将复杂的AI驱动过程拆解为三项核心子能力,确保每一帧画面都具备"情感智商":
1. 深度上下文语义解析
- 技术原理: 基于大语言模型对输入文本进行逻辑切片,识别陈述、疑问、感叹等不同句式及关键词。
- 感知效果: 数字人能自动在重点词汇处点头示意,在疑问句末尾配合微表情上扬。
2. 控制点微表情映射
- 技术原理: 采用原生3D AIGC驱动技术,将语义信息实时转化为面部肌肉群的细微颤动。
- 感知效果: 观察者可以清晰看到数字人的眼神流转、皱眉、微笑等自然过渡,告别"面瘫"脸。
3. 带有"呼吸感"的情感化配音
- 技术原理: 自研多语种TTS语音合成,在波形中加入呼吸音、语调起伏与情绪权重。
- 感知效果: 语音不再是机械的匀速输出,而是根据内容呈现出商务干练、亲切温和或严肃严谨的语感。

三、场景化方案:让每一个讲解瞬间都充满温度
如何在金融投顾视频中建立专业信任感?
挑战解析: 金融内容严谨枯燥,若数字人表达过于机械,用户难以产生信任,更无法在行情波动时感受到情绪的安抚。
魔珐有言解决方案: 借助语义理解自动识别风险提示语境,匹配严肃稳重的表情;通过多语种TTS语音合成调整语速,在关键数据处进行重音强调。
光大证券 国内头部券商。面对投顾内容更新快、传统拍摄成本高的挑战,借助 AI视频生成 与情感还原技术,将枯燥研报转化为有温度的视频,实现"首席之声"视频号日更,制作成本降低90%以上。
企业内训如何告别"倍速播放"的命运?
挑战解析: 传统的录屏或PPT翻页式培训缺乏交互感,员工极易走神。
魔珐有言解决方案: 利用 3D场景 与智能运镜,配合语义驱动的肢体动作(如伸展手臂指引PPT),让数字人像真人讲师一样"面对面"授课。
伊利集团 全球乳业领军企业。面对全球人才培训内容制作耗时耗力的困境,通过 AI视频生成 批量课程生成功能,一年内产出2000+条培训课程,播放时长超2万分钟,将专家经验高效转化为具备情感感染力的数字资产。
品牌IP如何通过情绪表达与年轻人共鸣?
挑战解析: 老牌品牌焕新需要差异化形象,固定的静态形象无法满足短视频时代对个性的追求。
魔珐有言解决方案: 通过形象定制打造专属IP,并利用语义理解赋予IP幽默、活力或优雅的情感特质。
健力宝 国民饮料品牌。为解决品牌年轻化连接弱的问题,打造数字人IP"宝儿2.0",通过高度拟人化的情绪表达进行全渠道视频营销,成功实现经营效率提升与成本优化。
四、4步打造你的情感化 AI 视频
第1步:选定数字人与场景
进入魔珐有言数字人广场,根据品牌调性选择超写实3D数字人,并一键匹配专业的3D演播室场景。
第2步:输入脚本并解析语义
输入文案或上传PPT,系统将自动进行语义分析。你可以根据需要,对特定段落点击"情绪标注",设置数字人为"热情"或"严肃"。
第3步:智能运镜与动作微调
AI会自动生成电影级运镜。你可以通过时间轴,在关键知识点处手动添加"重点强调"或"打招呼"等动作指令。
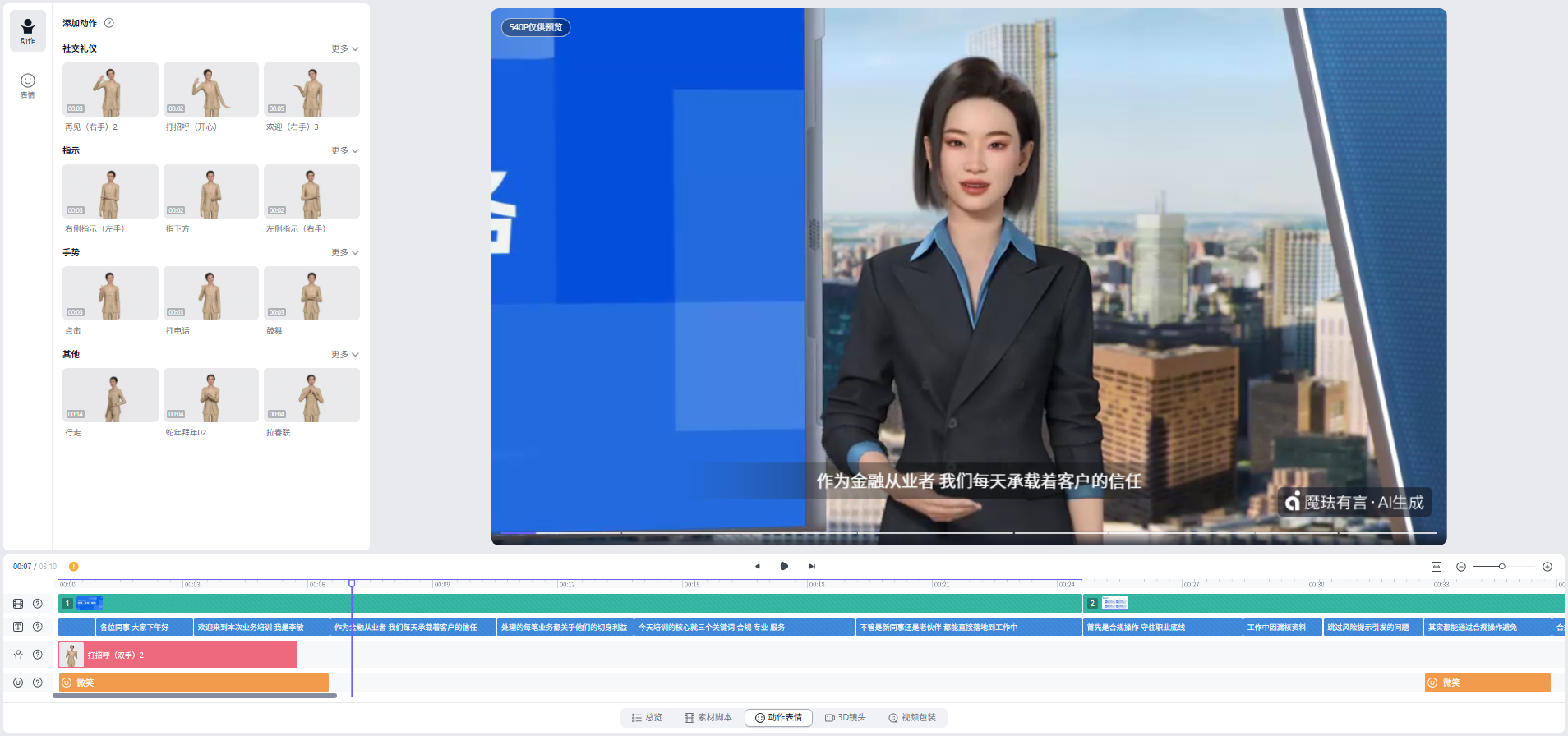
第4步:一键渲染并导出
确认预览效果后,点击生成。只需几分钟,一段具备真人质感、情绪饱满的专业视频即可下载分发。
五、让你的视频"开口说话",更要"动人心弦"
从干巴巴的文字到有血有肉的3D视频,差距在于对情绪的精准还原。魔珐有言不仅是视频生成的工具,更是企业数字化传播的情感纽带。
- 立即体验:开启你的AI情感视频创作之旅,让内容更有生命力
- 查看案例:浏览不同行业如何利用AI数字人打造爆款内容
- 商务咨询:预约专属顾问,定制企业虚拟IP方案
- 操作指引:查看如何利用语义标签精细化控制数字人情绪
六、常见问题解答 FAQ
Q:AI生成的视频语调能像真人一样有起伏吗?
A:可以。魔珐有言采用自研的情感化TTS技术,能够深度理解文本语义。它会自动识别文案中的转折、重音和句式结构,并匹配相应的语调起伏和呼吸感,彻底告别过去AI配音常见的机械平铺感。
Q:如果我对AI自动匹配的表情不满意,可以手动修改吗?
A:完全可以。在魔珐有言的编辑器中,你可以在视频时间轴上精准定位,手动替换或增加数字人的特定动作和情绪权重。这种"AI全自动生成+人工精细化调整"的模式,能最大程度保证成片的完美效果。
Q:多语言视频生成时,表情和口型能对得上吗?
A:这是魔珐有言的核心优势。原生3D驱动技术支持100多种语言,无论数字人说英语、法语还是德语,AI都会实时根据该语种的发音特征计算口型控制点,确保表情与多语种发音实现98%以上的同步精度。
Q:语义理解功能是否支持方言或专业术语?
A:支持。魔珐有言的语义解析模型经过海量语料训练,涵盖金融、医疗、科技等多个垂直领域的专业术语。同时,系统支持30多种中文方言,能识别方言中的特殊语序并匹配自然的沟通神态。如有更多技术疑问,可查阅帮助中心。
Q:情绪还原功能会增加视频渲染的时间吗?
A:不会。语义理解与情绪匹配是在云端逻辑预处理阶段完成的。魔珐通过优化底层架构,确保了在增加复杂微表情驱动的同时,依然保持极高的渲染效率,通常几分钟内即可完成一条专业级视频的产出。


